Svaldropbox#
Svaldropbox is written in Python code and can be downloaded from the Svaldropbox repository on the Svalbox organisation GitHub:
https://github.com/svalbox/svaldropbox
It is important to install the correct Python codes and libraries, and for that reason we have put together an environment file. An environment file results in an exact copy of another person’s working environment, thus saving time!
Requires Python installation
Please visit the Python tutorial on how to set up a dedicated environment and install Python. This is needed for the code to work. Make sure to install the Svaldropbox environment in conda.
Jupyter Notebook#
Open Visual Studio Code, then open the folder/directory where you placed the Svaldropbox repository.
Fig. 13 Launch VSC and open the correct folder.#
We will be using the Batch uploader to add Svalbox digital data sets to the Svalbox Digital Model Database. Proceed by opening the batch_processing.ipynb file. Then select the correct runtime environment for it, being the svaldropbox environment we created earlier Fig. 14.
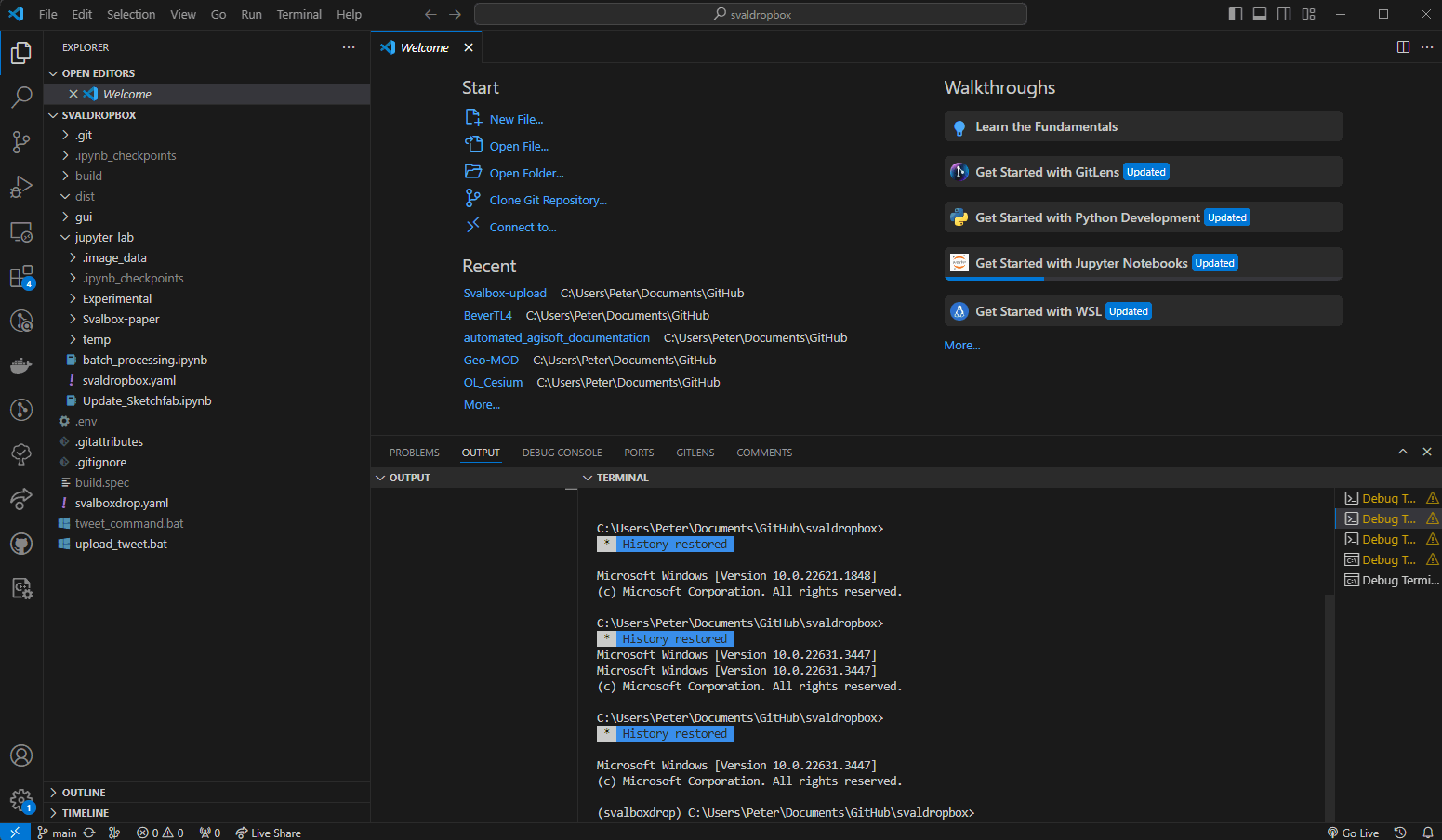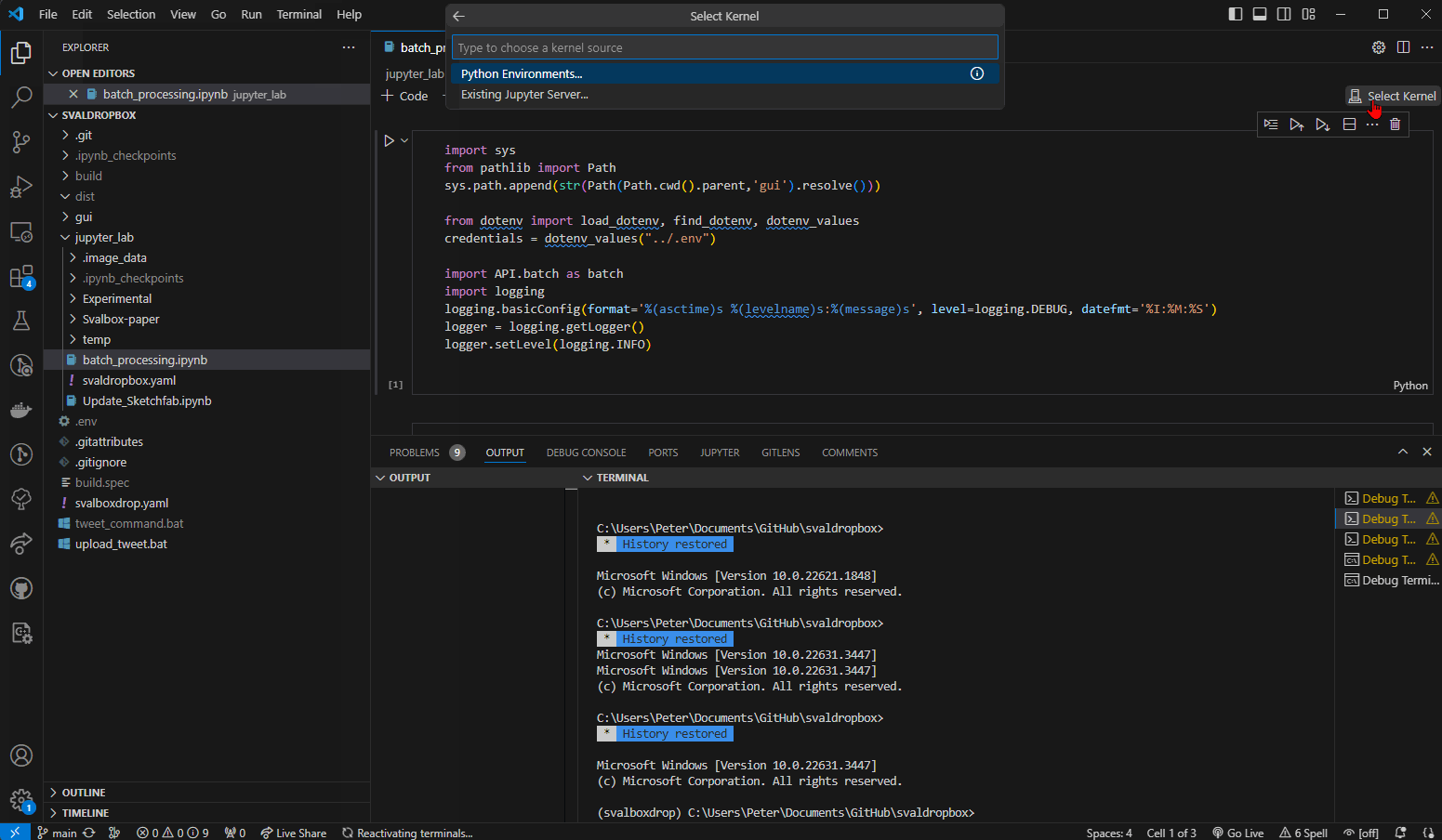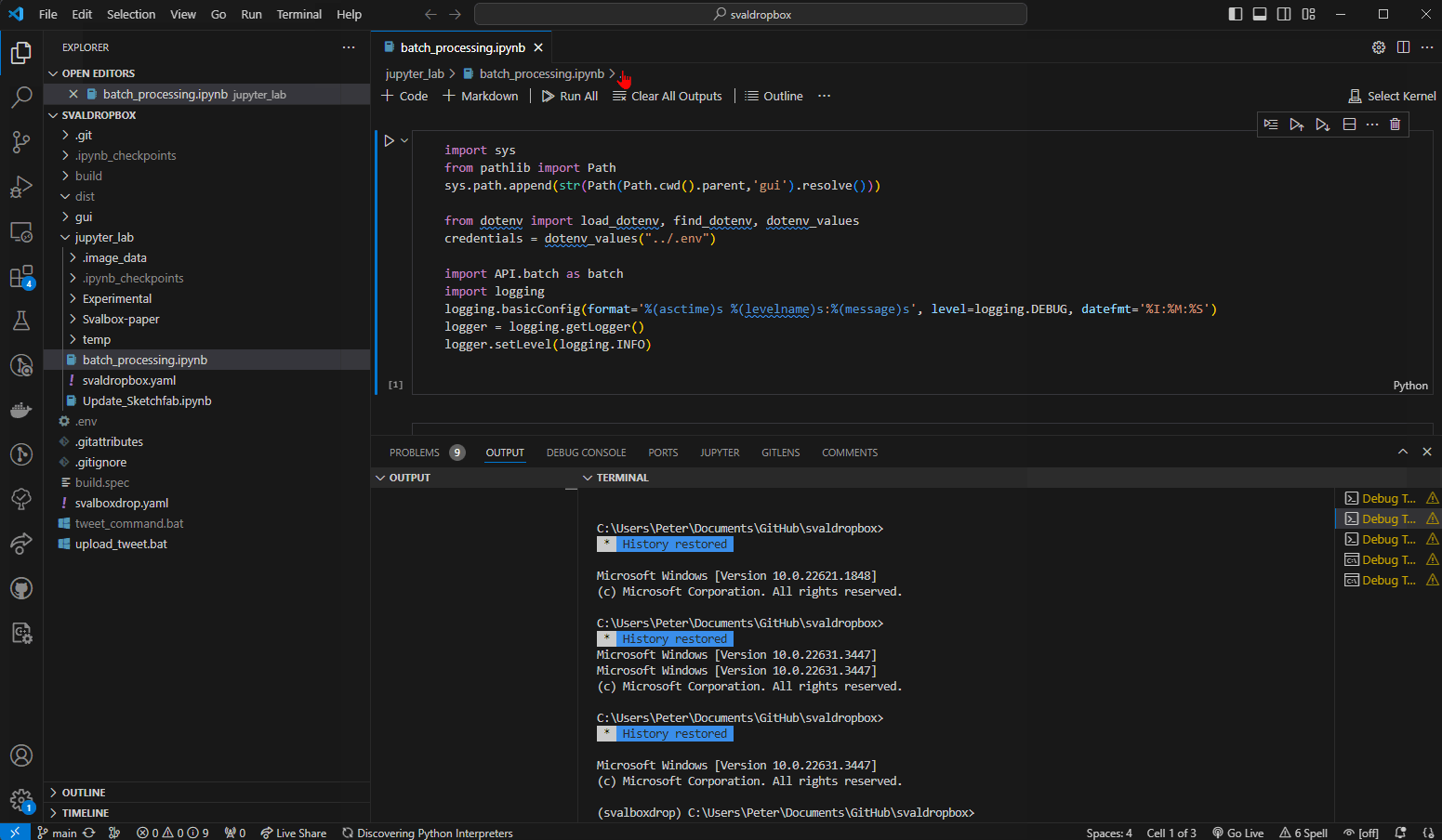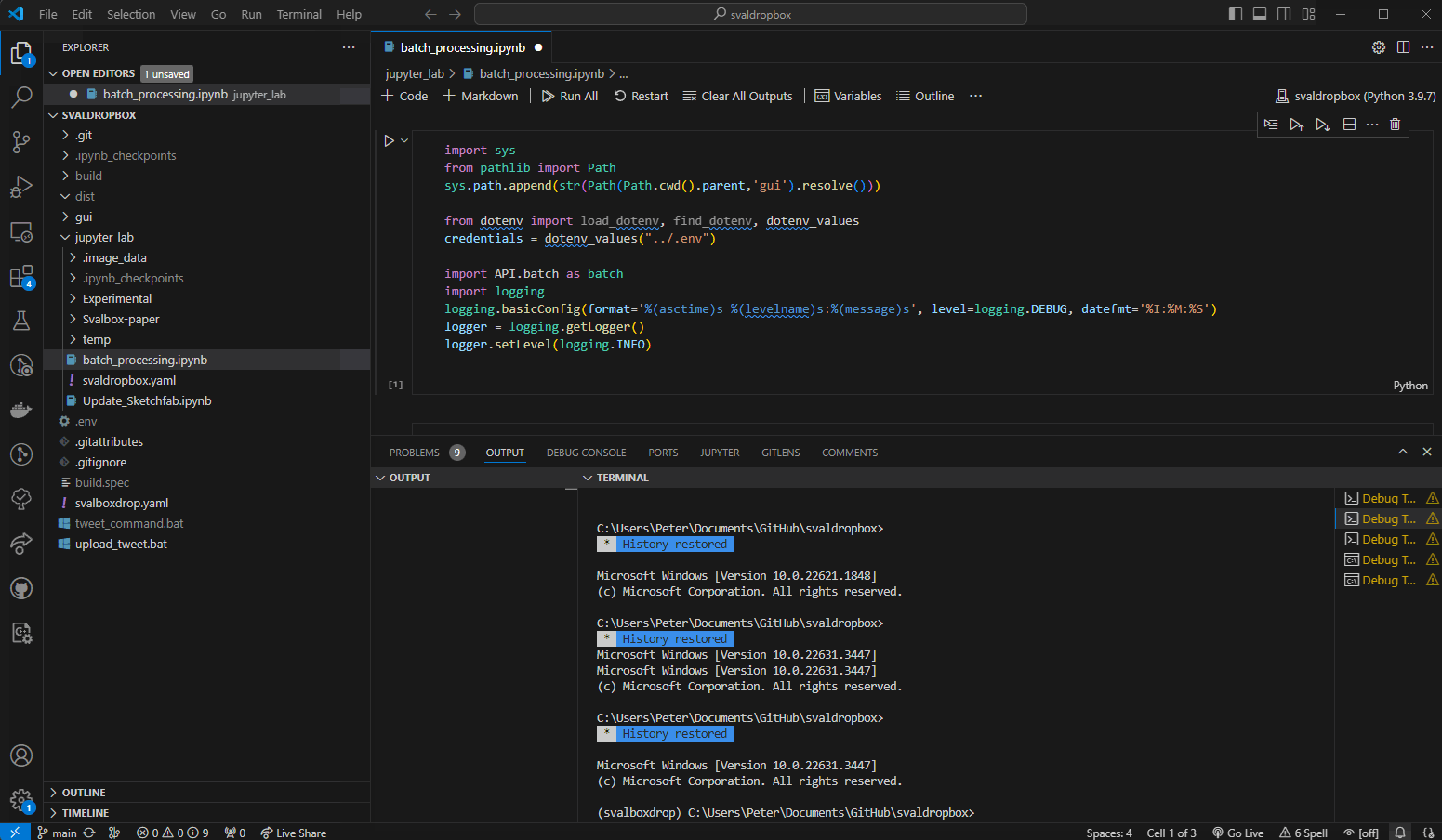
Fig. 14 Double click a file to open it for editing/running. Make sure to select the correct Python environment (in this case svaldropbox) from the Interpreter dropdown.#
batch_processing.ipynb#
The Batch_processing.ipynb file contains 3 so-called code blocks. Each is discussed briefly below.
import sys
from pathlib import Path
sys.path.append(str(Path(Path.cwd().parent,'gui').resolve()))
from dotenv import load_dotenv, find_dotenv, dotenv_values
credentials = dotenv_values("../.env")
import API.batch as batch
import logging
logging.basicConfig(format='%(asctime)s %(levelname)s:%(message)s', level=logging.DEBUG, datefmt='%I:%M:%S')
logger = logging.getLogger()
logger.setLevel(logging.INFO)
The first code block sets the correct system paths and imports various libraries that are needed for running the batch uploader (first 3 lines). The code block then loads credentials from an .env file in lines 5 and 6. The code block also imports the batch uploader script from the Svaldropbox API library, and then sets up basic logging (lines 8-12).
cl = batch.command_line(
username = credentials["SVALDROPBOX_USERNAME"],
password = credentials["SVALDROPBOX_PASSWORD"],
host ="localhost", # if running remotely on the UNIS network, replace "localhost" with "svalbox"
port ="5433",
logger = logger
)
This code block initialises the batch class and sets up the environment for updating the databases.
cl.load_from_folder(r"\\svalbox\Svalbox_DB\curated\svaldropbox")
This code block reads all DOM configuration files described in The configuration file that are placed in the specified folder. It goes through these one by one and adds them to the Svalbox databases. If problems arise, it will move the config folder to a labeled “failed”, otherwise it places the processed configurations in “success”.
environment password file#
As seen in the code, the code assumes that a specific .env file is present in the root folder of your svaldropbox folder. You should also have noticed by now that this file is not found in the Github repository - and with good reason! This file contains your secrets (i.e., database username and password access), and should never be uploaded. Your secrets are found in the passwordmanager, and will need to be copied over into your very own .env file.
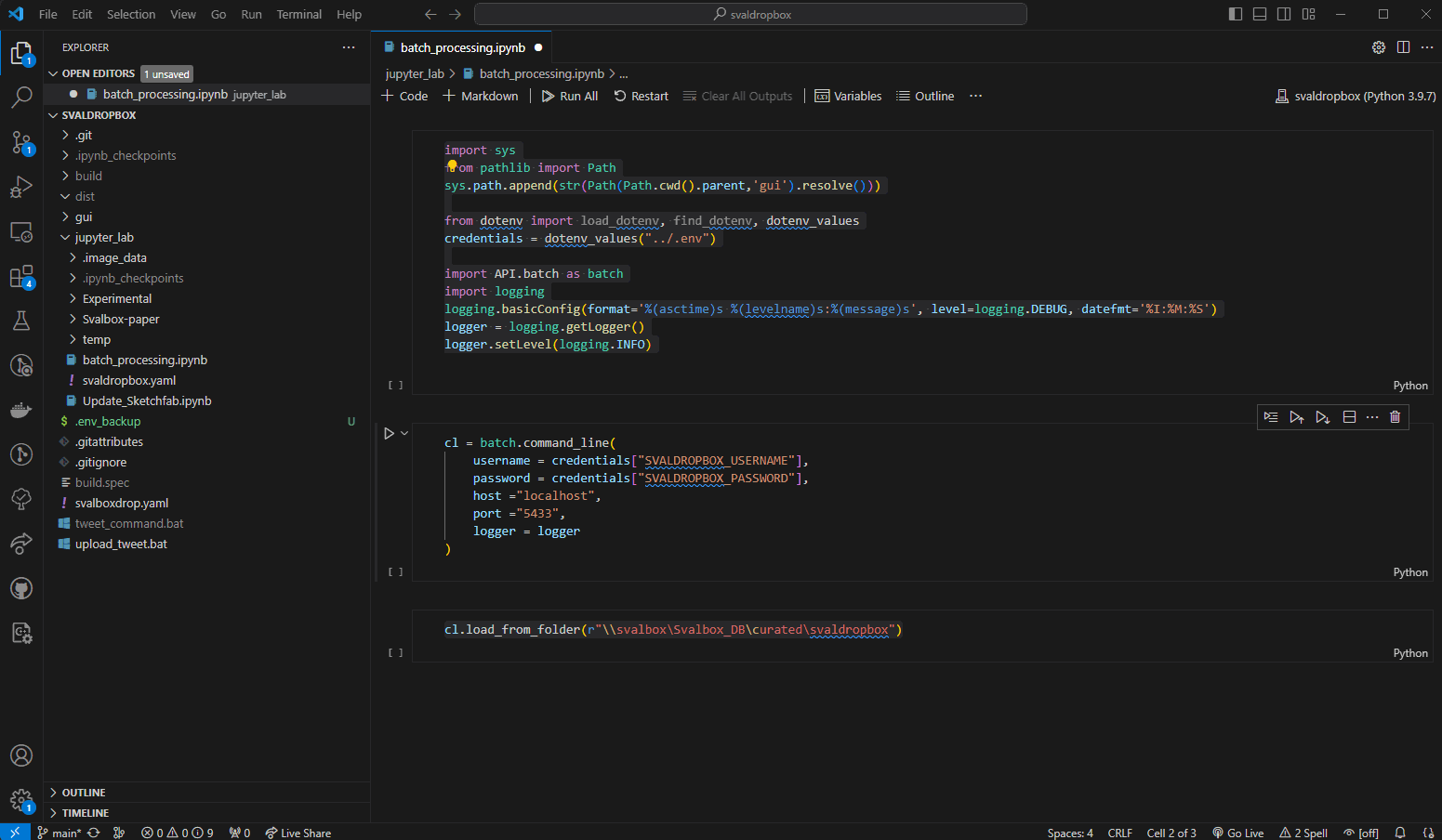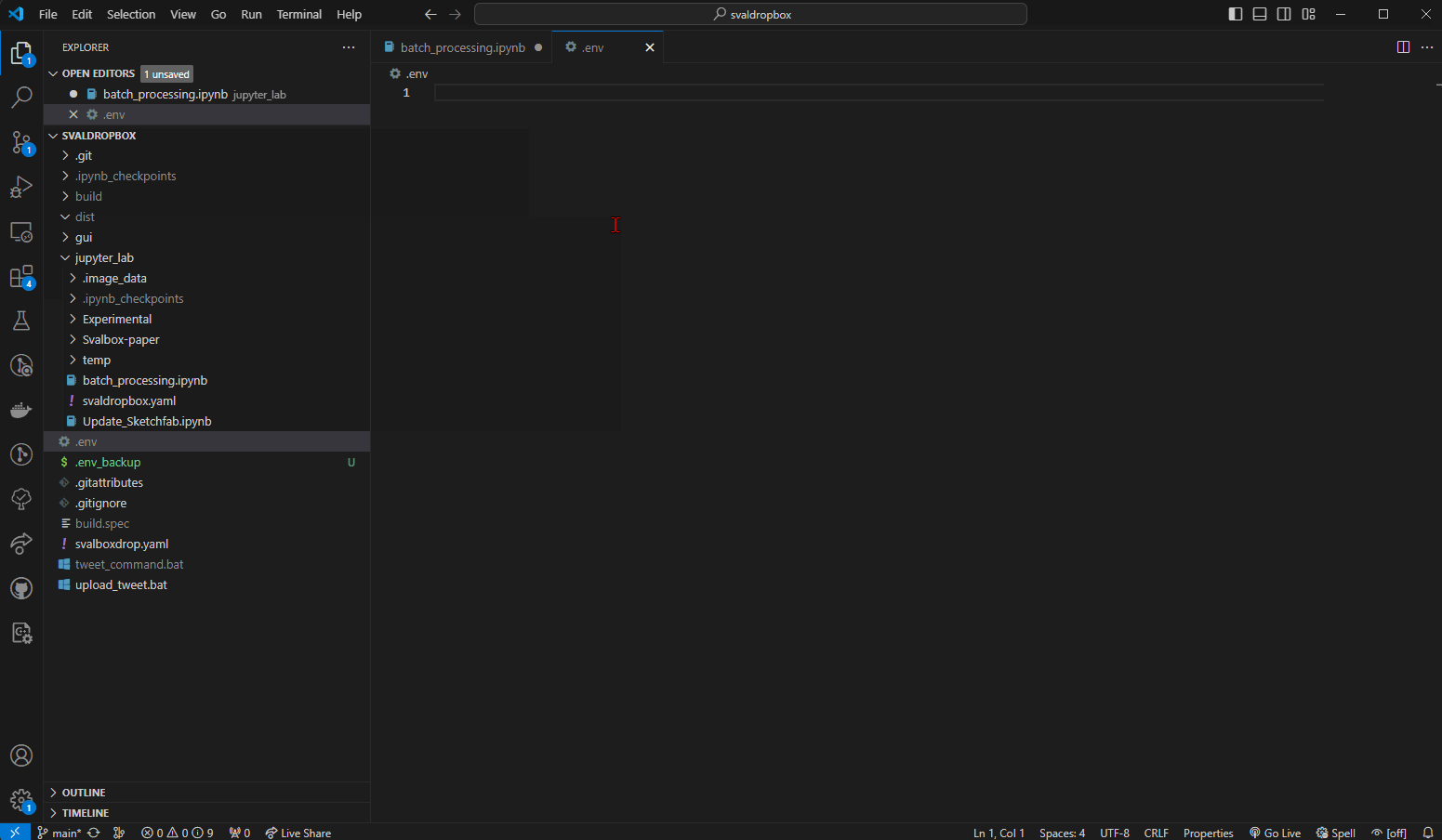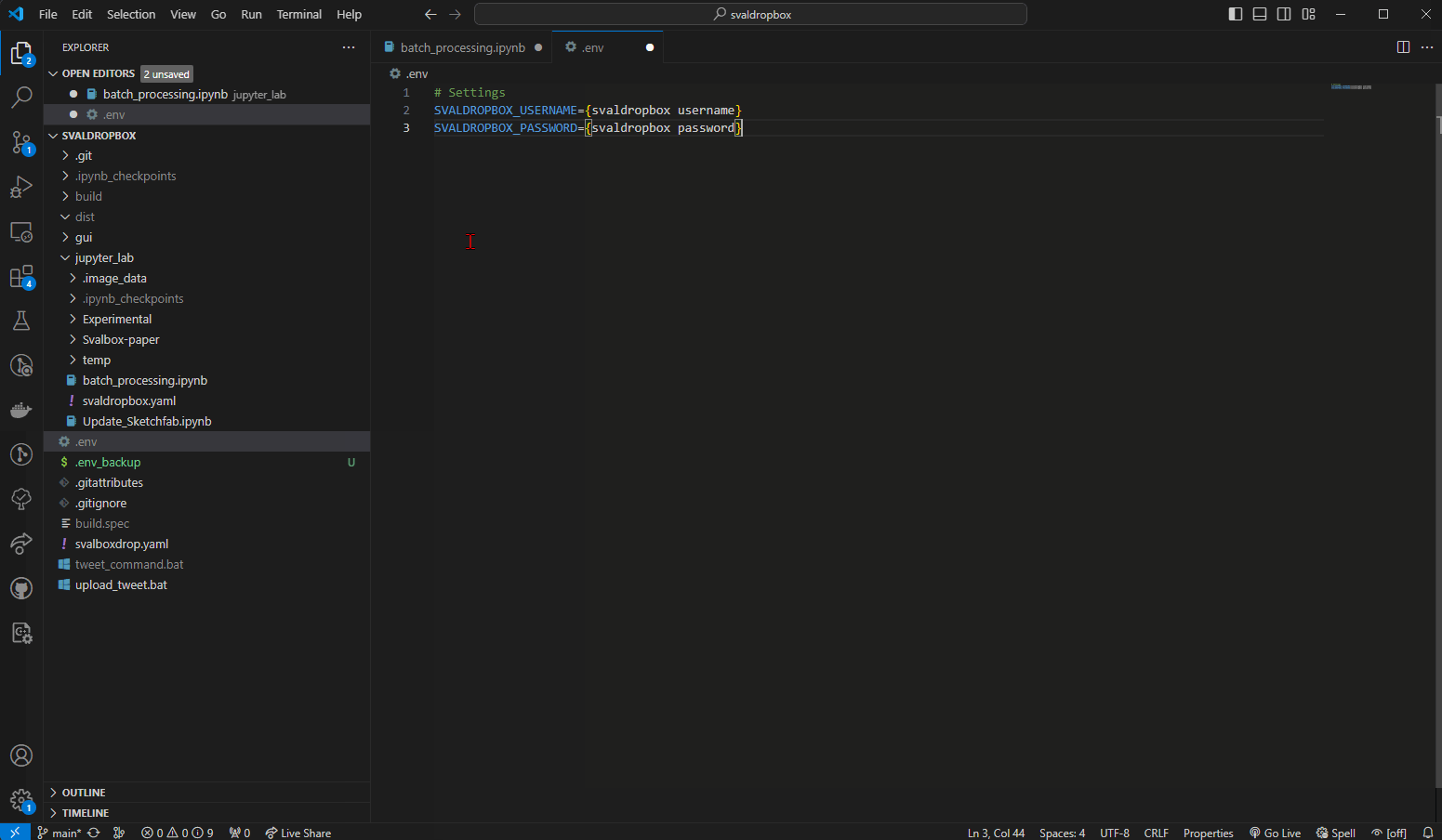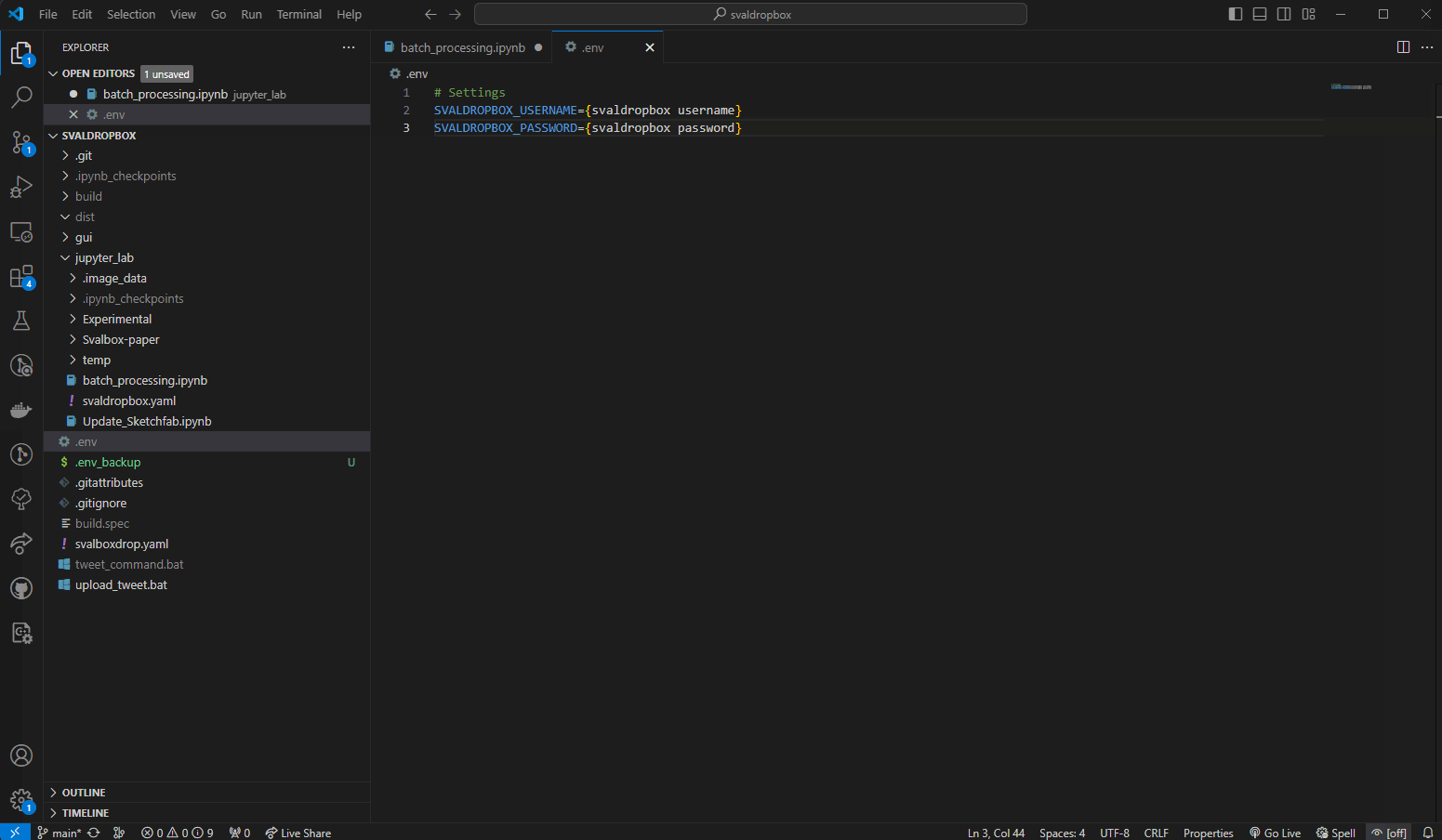
Fig. 15 Creating the .env file in the project root.#
Right click the explorer within VSC to create a new file in the root. Give it the .env name and copy paste in the information below. Then modify your username and password (including removing the brackets) before saving.
# Settings
SVALDROPBOX_USERNAME={svaldropbox username}
SVALDROPBOX_PASSWORD={svaldropbox password}
Updating the database#
You are now ready to upload the data to the databases. Place the The configuration file files in the directory specified in batch_processing.ipynb code block 3. Then run each of the code blocks by pressing Run All in the upper menu.
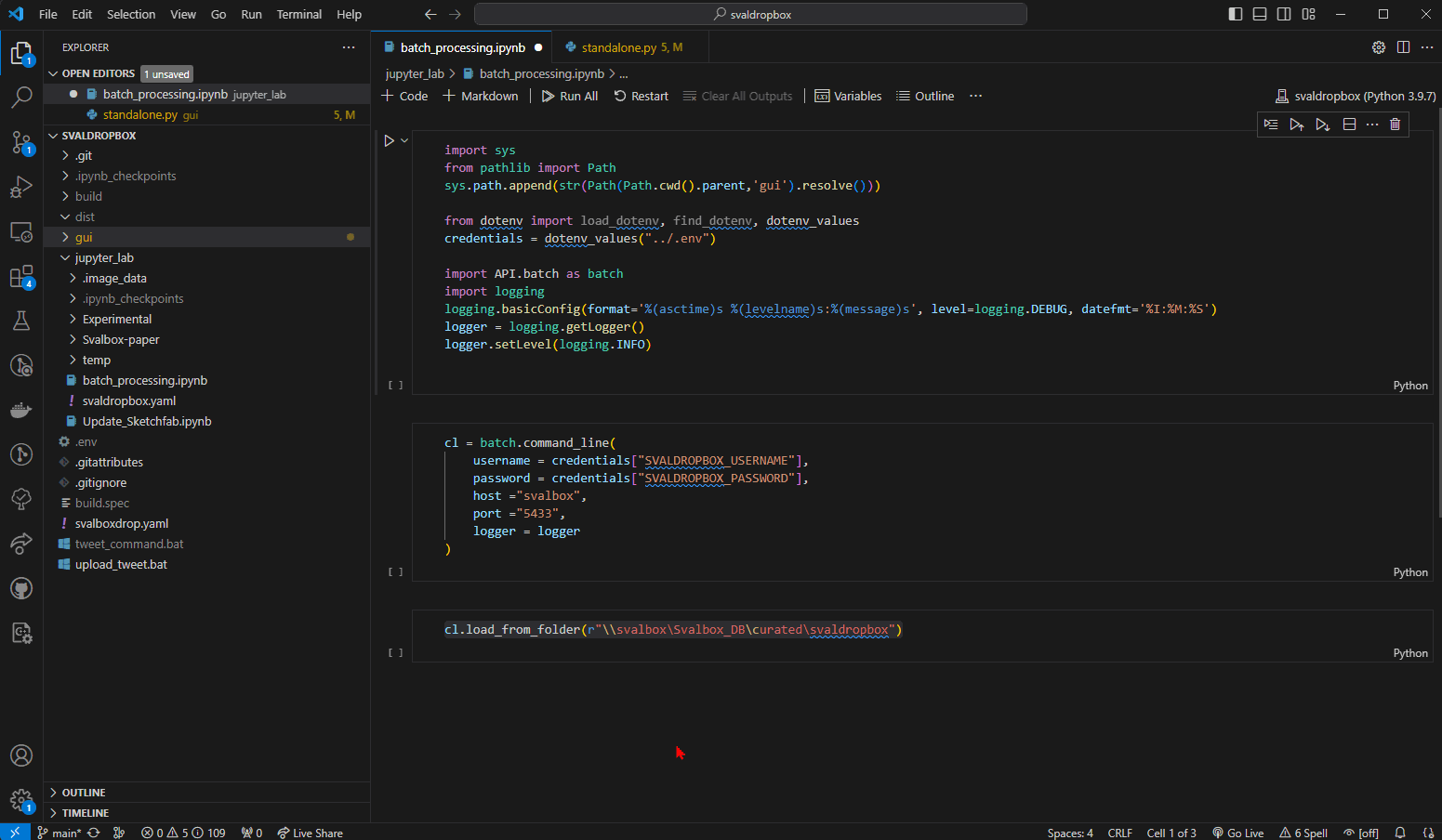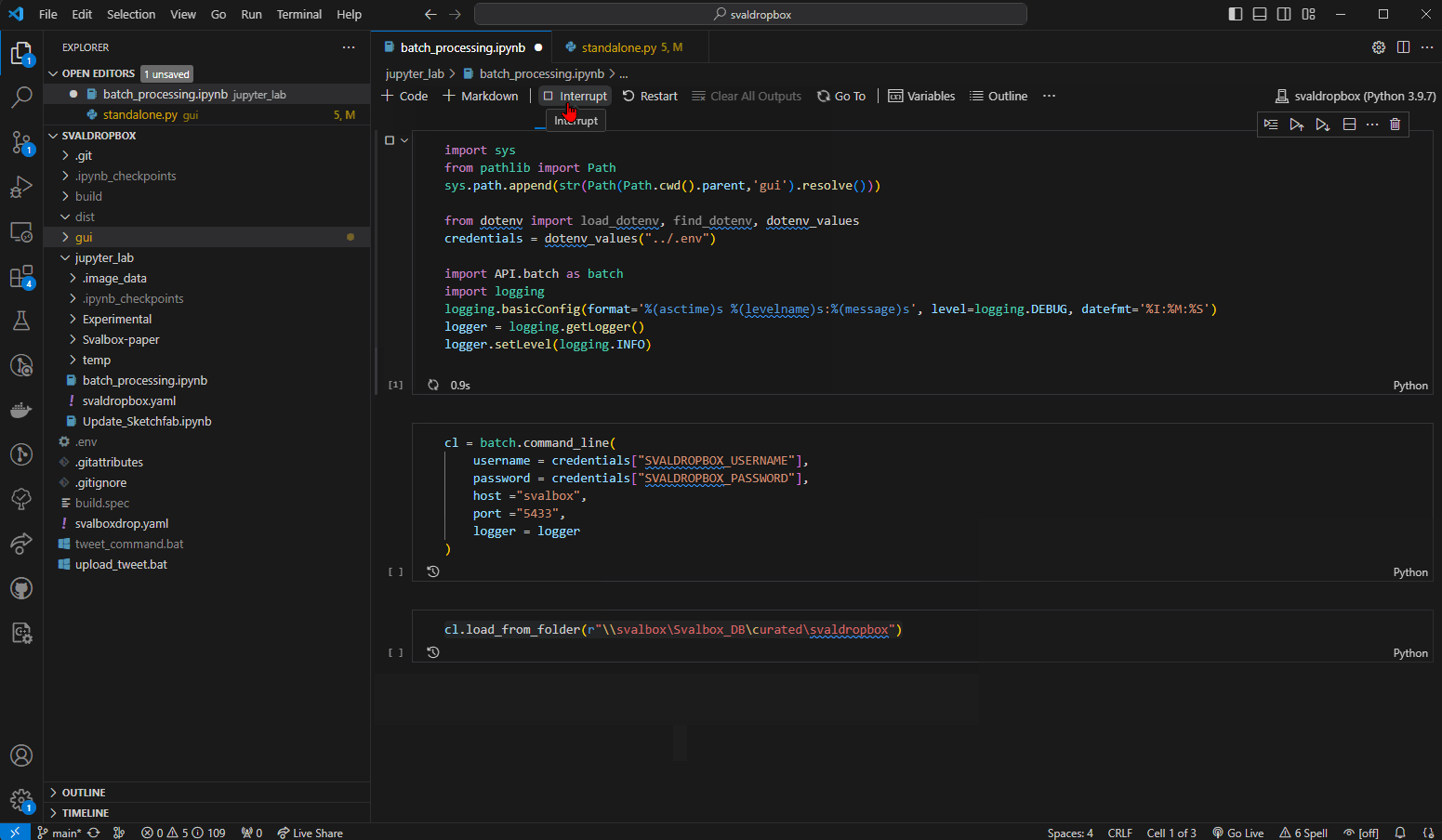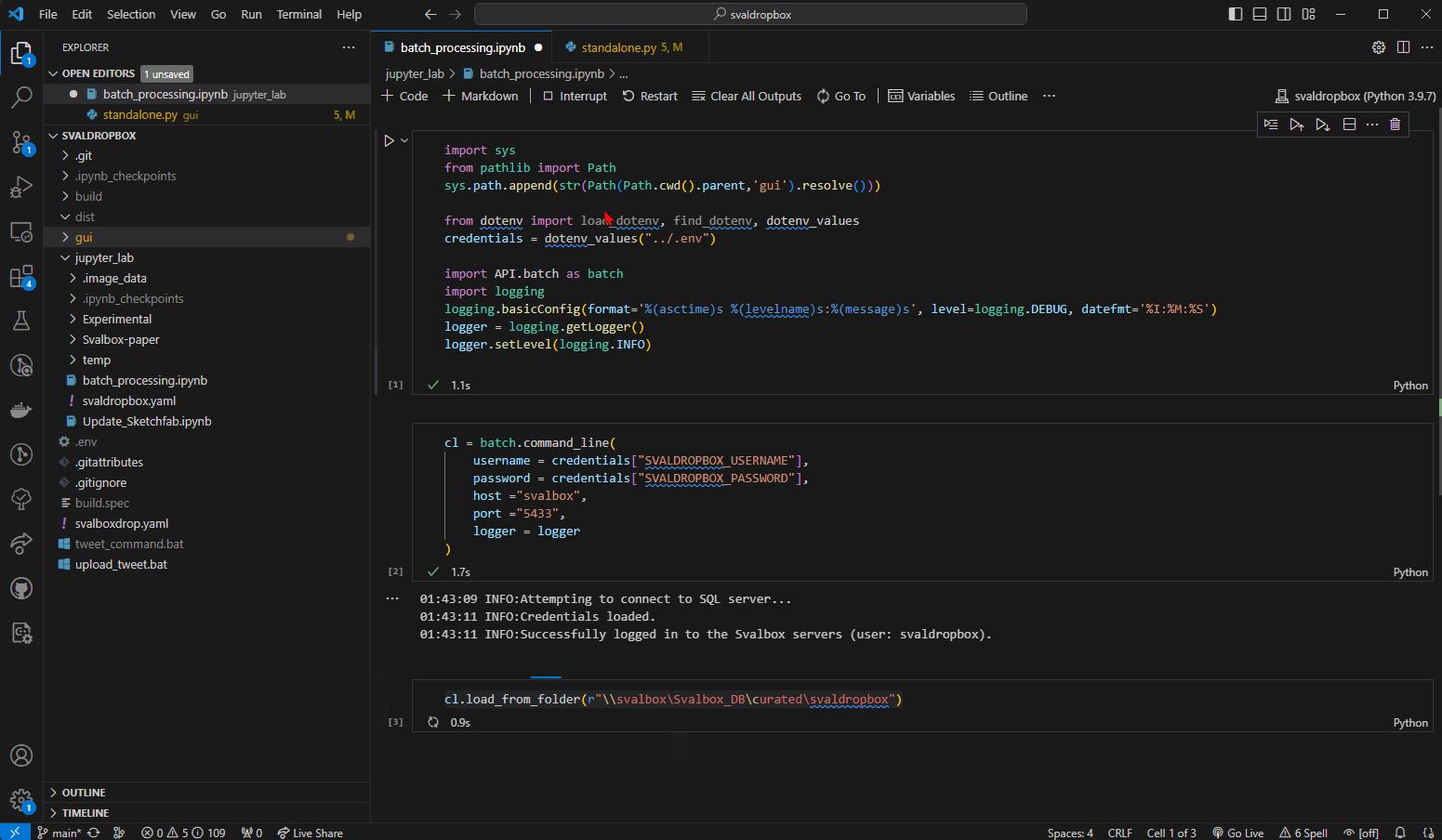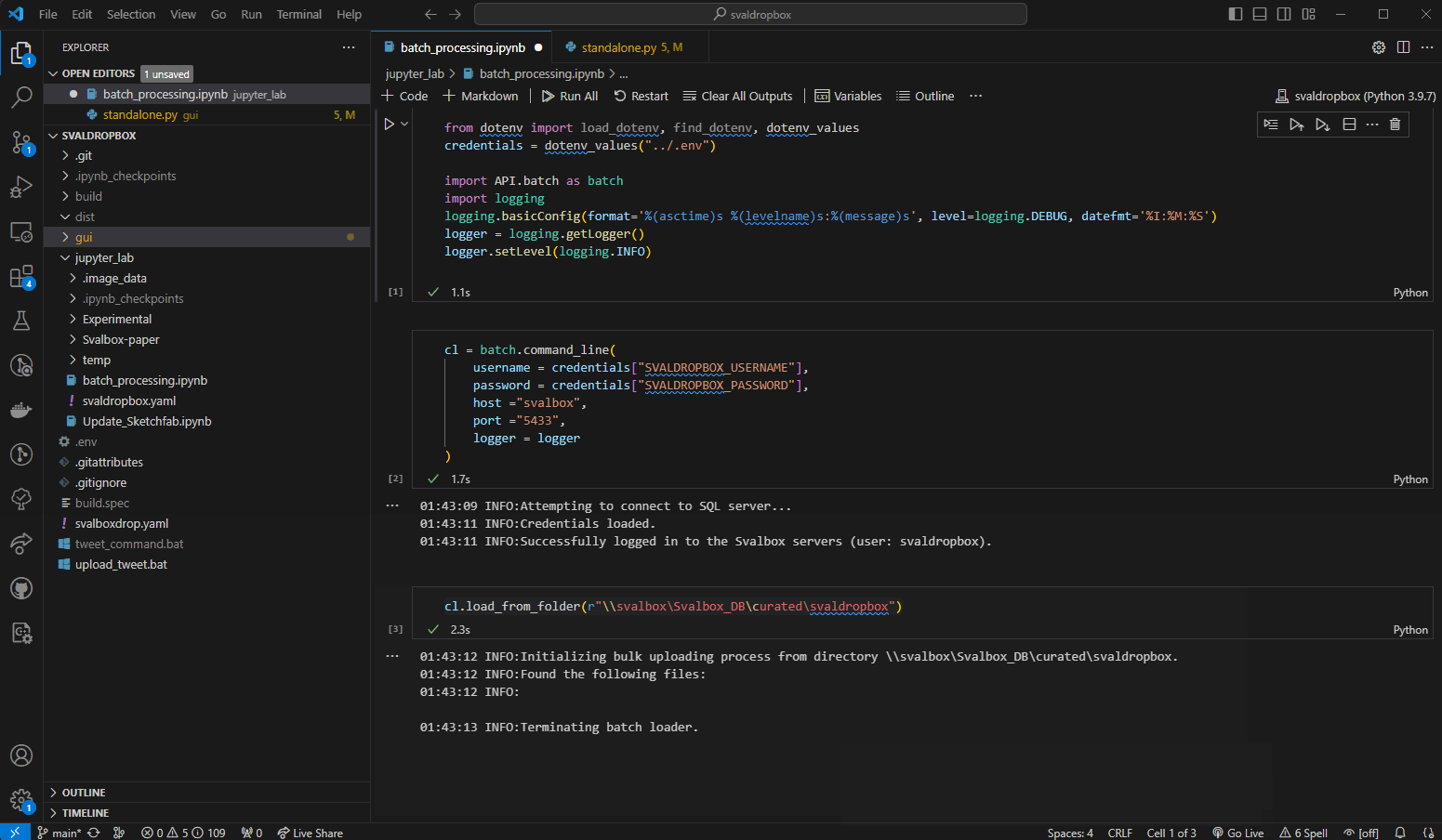
Fig. 16 Running all 3 code blocks without error. In this case, no config files were found in the specified folder (as reported by the logging).#
If all went well, you should see information be printed below each code block. The model outlines should also show up on Svalbox.no/map, if the uploaded data included DOMs.
Experiencing issues?
The scripts notify you of any issues encountered in the files. Most issues are so-called human errors; these include mistakes and typos in the configuration file, or for example specifying the wrong folder in block 3. Other issues may be harder to understand without looking at the code underneath. If such errors occur, it is recommended to take a screenshot of the error message and post this in the Github Svaldropbox bug tracker. That way someone can take a look at what is going on and help out, possibly by updating the code.
Visit the tracker here: svalbox/svaldropbox#issues
Finalise the upload#
Once you have verified the database has been successfully and correctly updated, it is time to head back to Zenodo. As part of the uploading procedure to the database, Zenodo’s metadata has been corrected and updated. Please verify that this is indeed the case. A quick way to check is to check the Title, which should resemble something like this:
Svalbox-{type}_{year}-{number}
in which {type} can be either DOM or DCM, {year} corresponds to the year of acquisition, and {number} corresponds to the number of said data set that was uploaded.
So, the 40th DOM uploaded in 2020 would get the following name: Svalbox-DOM_2020-0040.
Reupload changed data sets!
As part of the database procedure, several of the files have been updated that thus need to be replaced in Zenodo. The same goes for files that were manually edited - upload these again, too! Files that typically change:
metashape.zip
both processing reports
export.zip
Once all is verified and changed files have been updated, you may finally press Accept and publish to finalise the upload request. The data is now FAIRly available through Zenodo and registered in the Svalbox databases - well done!